



服务热线
15527777548/18696195380

发布时间:2022-05-25
简要描述:
SRC挖掘有很多平台,比如EDUSRC,比如公益SRC:补天、漏洞盒子等,还有就是一些企业SRC。对于挖掘src的小伙伴来说第一步都是对资产进行收集,所以本篇文章首先介绍一下SRC的上分思路,...
SRC挖掘有很多平台,比如EDUSRC,比如公益SRC:补天、漏洞盒子等,还有就是一些企业SRC。
对于挖掘src的小伙伴来说第一步都是对资产进行收集,所以本篇文章首先介绍一下SRC的上分思路,然后会具体讲解一下信息收集的思路。
对于公益SRC来说,会存在各种各样的漏洞,SQL注入、反射XSS、存储XSS、任意注册、cms通杀、弱口令还有逻辑漏洞,公益SRC主要比拼的无非就是手速,手速决定一切,提交的最多的一般还是sql注入、弱口令、和cms通杀。公益SRC想要冲榜的话可以选择一些有大的安全活动的时间,大佬们去参加安全活动,这个时候可以取巧,上榜会稍微轻松一点。对于公益SRC来说,想要冲榜就不能在一个站上浪费大量时间,公益SRC对洞的质量要求不高,所以只要 花时间,还是可以上榜的。
谷歌镜像站:http://scholar.hedasudi.com/
SQL注入的话主要通过google语法或者fofa进行搜索查找,使用inurl关键字在谷歌中搜索。
如:inurl:php?id=、inurl:asp?id、inurl:Show.asp?ID= 等等。
注意:不管是使用Google和fofa进行特定网站搜索,还是进行信息收集,只使用一种关键字对站点去进行查找是绝对无法找全的,关键字有很多,思路也有很多,思维不能局限住,要不断地去变换。
可以尝试这么去构造Google语句:地区inurl:"type_id=1"、行业inurl:"ptherinfo.asp?id=1"
地区和行业可以任意替换,在提交漏洞的地方通常会有一个选项,选择漏洞所属地区和所属行业,可以以此为准一个一个找,之后还可以将php替换为asp、aspx、jsp等站点。
在对某站点进行测试SQL注入的时候,先通过一些方式测试是否可能存在漏洞,然后可以直接sqlmap一把梭,也可以手工测试,然后提交漏洞。
对于XSS来说可能并不好找,所以我认为没必要太刻意的去挖XSS,不管是反射型还是存储型,所以我认为在测试sql注入的时候顺带对XSS进行测试就好了。但是如果想要专门挖xss,在实战中学习,也可以通过和sql注入一样的语法,改变几个关键字就好了,比如:地区inurl:"search?kw="、inurl:'Product.asp?BigClassName'
如果你想要挖任意注册漏洞,那么你首先需要了解什么是任意注册,任意注册是一种程序设计的缺陷,顾名思义就是随便注册,不需要什么条件,注册处无任何验证。Google语法关键词:地区/行业inurl:"register"、地区/行业inurl:"regp.asp"、Reg.asp、userreg.asp、reg1.asp等。任意注册算是低危漏洞,不过也有两分。任意注册没多少人挖,可以尝试挖掘。去漏洞盒子提交漏洞的时候,可以看下漏洞类型,可以挑一些你认为漏洞比较冷门没人挖并且普遍存在的去下手。
普通人找通杀的思路无法就是百度谷歌搜索cms通杀,
但是其实这样的效率并不高,通杀也找不到几个,这里建议可以去一些漏洞文库,
建议多进行漏洞复现,多实战,多积累实战经验,复现漏洞也是一种积累。
尝试弱口令的过程比较繁琐,但是最好老老实实的手工上分,百度或者谷歌语法搜索后台站点。
如:山西inurl:"后台"
可以尝试:
账号:admin/test/cs/ceshi/test01等 密码:admin/123456/a123456/admin123/admin123456等。
也可以借助fofa对后台站点进行搜索:
title="后台管理" && country="CN"
fofa语句(查找edu里的管理系统):
"管理系统" && org="China Education and Research Network Center"
对于EDUSRC来说,想上分的同学主要有两种方式:
1.挖通用性漏洞。找一些站点或者系统,被广大学校所使用,覆盖率很高,再去对这个站点或者系统进行漏洞挖掘,挖掘到之后就可以批量刷分。
2.定点打击。对一个学校埋头苦干,通过一些信息泄露或者一些学生的微博、朋友圈等,获取一些学生的相关信息,比如学号、身份信息号码、电话等等,尝试登入校园内网或者登录校园统一身份认证系统,对内网进行漏洞挖掘,直接日穿。
使用Google语法进行收集:
site:"edu.cn"
inurl:login|admin|manage|member|admin_login|login_admin|system|login|user|main|cms
查找文本内容:
site:域名 intext:管理|后台|登陆|用户名|密码|验证码|系统|帐号|admin|login|sys|managetem|password|username
查找可注入点:site:域名 inurl:aspx|jsp|php|asp
查找上传漏洞:site:域名 inurl:file|load|editor|Files
找eweb编辑器:
site:域名 inurl:ewebeditor|editor|uploadfile|eweb|edit
存在的数据库:site:域名 filetype:mdb|asp|#
查看脚本类型:site:域名 filetype:asp/aspx/php/jsp
迂回策略入侵:inurl:cms/data/templates/images/index/
渗透测试的本质就是信息收集,
信息搜集的广度决定了攻击的广度,知识面的广度决定了攻击的深度。
不管是进行SRC漏洞挖掘,还是做项目进行渗透测试,又或者是打红蓝对抗,一定要做好信息收集。
信息收集很重要,如确定资产,比如他有哪些域名、子域名、C段、旁站、系统、微信小程序或者公众号,确定好站点或者目标系统之后,就是常规的指纹识别,像中间件、网站,扫目录,后台,确定功能然后分析每个功能点上会有哪些漏洞,就比如一个登录页面,我们可以考虑的是爆破账号密码,社工账号密码,SQL注入,XSS漏洞,逻辑漏洞绕过等。
如果大家挖掘SRC的水平都是一样的或者说我们对于各种操作都是同样了解的,那么如果超越别人,如果你挖的比别人慢,那么你后期提交的漏洞会撞洞,然后忽略处理。在短时间内你无法去提升你的技术或者是挖掘一个新的思路,这个时候就体现了资产搜集的能力,信息搜集是最难的,也是最麻烦耽误时间的,且必须要实时去关注的一件事情。
一些常用网站:
ICP备案查询:https://icp.aizhan.com
权重查询:https://rank.aizhan.com/www.wondercv.com/
多地ping:https://www.ping.cn/d
whois查询:https://www.whois365.com/cn/ip/119.23.74.200
IP反查:https://www.ip138.com/iplookup.asp?ip=166.111.53.94&action=2
以xxx公司为例,根域名:xxx.cn
信息收集可以从多个领域来看:公司,子公司,域名,子域名,IPV4,IPV6,小程序,APP,PC软件等等
可以重点关注备案网站,APP,小程序,微信公众号,甚至是微博。
这里说一点小思路,首先可以找到官网,用cmd ping他的官网,可以看到IP地址,然后可以定位whois,whois中包含了用户、邮箱,以及购买的网段。
有了网段就可以进行一些主动信息收集,可以使用一些强大的资产测绘工具,goby的资产测绘还是很不错的,会有一些web服务,不用担心没有banner,往往这些没有banner的才有问题。
注意观察一下网站底部是否有技术支持:xxxx|网站建设:xxxx之类的标注,一些建站企业会出于知识产权保护或者是对外宣传自己的公司,会在自家搭建的网站上挂上技术支持等之类的标注,很多建站企业往往某种类型的网站都是套用的同一套源码,换汤不换药,运气不错的话,那我们的事件就秒变通用。
尽量多凑一点API,fofa可以找人借一些api,越多越好。
https://github.com/shmilylty/OneForAll
执行命令:
常用的获取子域名有2种选择,一种使用--target指定单个域名,一种使用--targets指定域名文件。
python3 oneforall.py --target example.com run
python3 oneforall.py --targets ./domains.txt run
python3 oneforall.py --target xxx.cn run
一款信息搜集工具,包含了很多的接口,包括zoomeyes、360quake
https://github.com/knownsec/Kunyu
JSFinder是一个在网页的JS文件中寻找URL和子域名的工具,在网站的JS文件中,会存在各种对测试有帮助的内容,JSFinder可以帮我们获取到JS中的url和子域名的信息,扩展我们的渗透范围。爬取分为普通爬取和深度爬取,深度爬取会深入下一层页面爬取的JS,时间会消耗的相对较长。
https://github.com/Threezh1/JSFinder
执行命令:python3 JSFinder.py -u http://www.xxx.cn-d -ou JSurl.txt -os JSdomain.txt
运行结束后会生成两个txt文本,Jsurl.txt为URL里面会有一些接口什么的,Jsdomain.txt为子域名
基于TamperMonkey的版本:https://github.com/Threezh1/Deconstruct/blob/main/DevTools_JSFinder/JSFinder.js
Layer、子域名收割机 进行挖掘
通过这些域名收集工具(layer子域名挖掘机、Maltego CE、wydomain、subDomainsBrue、sublist3r、subfinder)进行挖掘。
为了避免IP被封掉,直接使用在线的子域名爆破网站。
http://z.zcjun.com/
http://tool.chinaz.com/subdomain
https://dnsdumpster.com
https://github.com/lijiejie/subDomainsBrute
执行命令:
python subDomainsBrute.py -t 10 xxx.cn -o xxx.cn.txt
python subDomainsBrute.py -t 10 --full xxx.cn -o xxx.cn.txt //全扫描。
Kali和Windows环境下都可以装这个工具,Sublist3r是一个python版工具,其原理是基于通过使用搜索引擎,从而对站点子域名进行列举。
Kali:git clone https://github.com/aboul3la/Sublist3r
执行命令:python sublist3r.py -d 6pian.cn -o xxx.cn-sublist3r.txt
https://dnsdumpster.com/
非常好用的一个域名搜索网站,还会自动归纳同一个IP的多个域名。
http://z.zcjun.com
通过小蓝本进行查询:
https://www.xiaolanben.com/
https://www.qcc.com/
https://aiqicha.baidu.com/
https://www.tianyancha.com/
之前爱企查活动送了会员,可以更好的进行查询。
迅速查找信息泄露、管理后台暴露等漏洞语法,例如:
filetype:txt 登录
filetype:xls 登录
filetype:doc 登录
intitle:后台管理
intitle:login
intitle:后台管理 inurl:admin
intitle:index of /
查找指定网站,再加上site:http://example.com,例如:
site:example.com filetype:txt 登录
site:example.com intitle:后台管理
site:example.com admin
site:example.com login
site:example.com system
site:example.com 管理
site:example.com 登录
site:example.com 内部
site:example.com 系统
谷歌/必应:site:url.com
site:xxx.cn
如果发现检索出来的很多结果都是www,众所周知主站一般防御很严,如果我们不想看到主站可以直接 -www
site:xxx.cn -www
这样出来的结果会自动删去www
fofa语法
FOFA作为一个搜索引擎,我们要熟悉它的查询语法,类似google语法,FOFA的语法主要分为检索字段以及运算符,所有的查询语句都是由这两种元素组成的。目前支持的检索字段包括:domain,host,ip,title,server,header,body,port,cert,country,city,os,appserver,middleware,language,tags,user_tag等等,等等,支持的逻辑运算符包括:=,==,!=,&&,||。
如果搜索title字段中存在后台的网站,我们只需要在输入栏中输入title=“后台”,输出的结果即为全网title中存在后台两个字的网站,可以利用得到的信息继续进行渗透攻击,对于网站的后台进行密码暴力破解,密码找回等等攻击行为,这样就可以轻松愉快的开始一次简单渗透攻击之旅,而企业用户也可以利用得到的信息进行内部的弱口令排查等等,防范于未然。
例:搜索QQ所有的子域名:domain=“qq.com”
例:搜索host内所有带有qq.com的域名:host=“qq.com”
例:搜索某个IP上的相关信息:ip=“58.63.236.248”
ip=“111.1.1.1/8”
ip="111.1.1.1/16"
ip="111.1.1.1/24"
例:搜索title包含有“漏洞”的IP:title=“漏洞”
例:Apache出来了一个高危漏洞,我们需要去统计全球的Apache:server=“Apache”
例:搜索前段时间非常火的海康威视:header=“Hikvsion”
例:假如我想搜索微博的后台,域名为:weibo.com 并且网页内body包含“后台”:body=“后台”&& domain=“weibo.com”
&&:与body=“后台”&& domain=“weibo.com”提取域名为:weibo.com并且网页内body包含“后台”的网站,需要同时满足两个条件。
例:想要找非80端口 port!=“80”
!=:port!="80" 匹配端口不为80端口的服务
搜索证书(https或者imaps等)
例:百度公司为了检查自己的域名是否还有心脏出血漏洞可以使用语法:cert=“baidu”
搜索指定国家(编码)的资产
例:搜索中国的服务器 country=“CN”
注:country=“CN” country后面的规则为各国家的缩写,全球国家缩写如下连接:
https://zhidao.baidu.com/question/538403206.html
搜索指定城市的资产
例:搜索上海的服务器 city=“Shanghai”
注:搜索城市时填写城市的全程,首字母必须大写
例:搜索centos所有主机 os=“centos”
了解了基础查询我们再来说说高级查询,就是多个基础查询语句用逻辑连接符拼成的语句,例如我们要搜索上海的Discus组件,搜索语句时 (title="Discuz" || body="count="Discuz")&&city="Shanghai"
&&:逻辑与
||:逻辑或
上面的语句意思为 (title="Disuz" ||body="content="Discuz") 与city="Shanghai" 这两个条件必须同时满足,(title="Discuz" ||body="dontent="Discuz") 中的title=”Discuz“与body=”content=\”Discuz“ 满足一个即可
FOFA可以从不同维度搜索网络组件,例如地区,端口号,网络服务,操作系统,网络协议等等。目前FOFA支持了多个网络组件的指纹识别,包括建站模块、分享模块、各种开发框架、安全检测平台、项目管理系统、企业管理系统、视频监控系统、站长平台、电商系统、广告联盟、前端库、路由器、SSL证书、服务器管理系统、CDN、Web服务器、WAF、CMS等等
尤其现在支持icon图标、logo搜索,非常方便,fofa搜索语法与shodan类似
title="abc" 从标题中搜索abc。例:标题中有北京的网站
header="abc" 从http头中搜索abc。例:jboss服务器
body="abc" 从html正文中搜索abc。例:正文包含Hacked by
domain="qq.com" 搜索根域名带有qq.com的网站。例:根域名是qq.com的网站
host=".gov.cn" 从url中搜索.gov.cn,注意搜索要用host作为名称。例:政府网站, 教育网站
port="443" 查找对应443端口的资产。例:查找对应443端口的资产
可以安装shodan chrome插件,方便进行查看和使用。
微步在线的反向IP查找域名十分好用
https://crt.sh/
http://censys.io/
https://phpinfo.me/domain
http://dnz.aizhan.com
旁站就是在同一台服务器上搭建的多个网站,使用同一个IP地址。在目标网站无法攻击成功时,若他的旁站可以成功攻击并获取相应的系统权限,这势必会影响到目标网站的安全性,因为已经获取到同一台服务器的权限了。
https://chapangzhan.com/
https://ipchaxun.com/
从微信小程序入手,进行测试
https://app.diandian.com
https://www.qimai.cn/
七麦还可以切换苹果和安卓,获取下载链接apk丢进模拟器
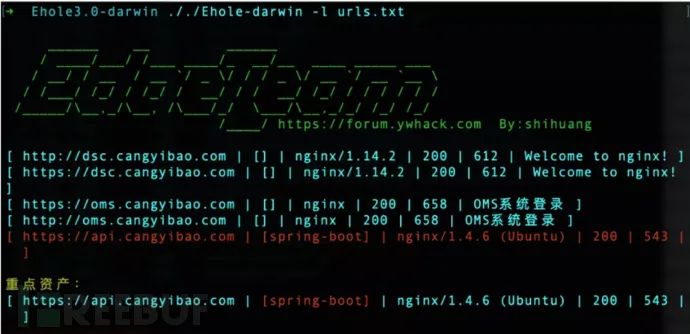
https://github.com/EdgeSecurityTeam/EHole
使用方法:
./Ehole-darwin -l url.txt //URL地址需带上协议,每行一个
./Ehole-darwin -f 192.168.1.1/24 //支持单IP或IP段,fofa识别需要配置fofa密钥和邮箱
./Ehole-darwin -l url.txt -json export.json //结果输出至export.json文件
https://github.com/s7ckTeam/Glass
使用方法:
python3 Glass.py -u http://www.examples.com// 单url测试
python3 Glass.py -w domain.txt -o 1.txt // url文件内
http://whatweb.bugscaner.com
主站没识别出来,但是其他子站可以丢进来看看
http://finger.tidesec.com
此工具需要go环境
https://github.com/lcvvvv/kscan
http://www.yunsee.cn/info.html
云悉可以在线搜索子域名、IP段、CMS指纹等信息
https://github.com/EASY233/Finger
https://github.com/EdgeSecurityTeam/EHole
github敏感信息泄露一直是企业信息泄露和知识产权泄露的重灾区,安全意识薄弱的同事经常会将公司的代码、各种服务的账号等极度敏感的信息【开源】到github中
这里可以利用github找存在xxx.cn这个关键字的代码,这样可以收集到的方面更广
GSIL项目:
https://github.com/FeeiCN/GSIL
通过配置关键词,实时监控GitHub敏感信息泄露情况,并发送至指定邮箱
https://myssl.com
https://crt.sh/
在shodan搜索中有一个关于网站icon图标的搜索语法,http.favicon.hash,我们可以使用这个语法搜索出使用了同一icon图标的网站。
由于hash为一个未知的随机数,
所以是无法通过输入一个确定的hash值来搜索带有指定图标的网站的,
只能通过查看一个已经被shodan收录的网站的hash值,来进一步获取到所有带有某icon的网站。
那么这里的用法就非常具有局限性,你只能是碰运气来找到你所需要查找的网站,因为shodan不一定收录了你想要搜索的网站。
那么如果shodan收录了某个IP,这个服务器带有某个icon图标,也可以搜索所有带有此icon的服务器IP
如果我像搜索带有这个icon的所有IP地址的话,可以先在shodan搜索这个IP。
注意:shodan中有一个功能,shodan的原始数据(Raw Data)功能。
点击详情里的View Raw Data,打开可以看到shodan所存储的关于这个IP的所有信息的原始数据。
关于icon hash的字段是:data.0.http.favicon.hash
这个数值就是http.favicon.hash:中所需要的搜索值。
根据上述得到的hash值,成功得到了所有待用这个icon的网站。
任意文件下载常用路径:
LINUX:
/root/.ssh/authorized_keys /root/.ssh/id_rsa /root/.ssh/id_ras.keystore /root/.ssh/known_hosts /etc/passwd /etc/shadow /etc/issue /etc/fstab /etc/host.conf /etc/motd /etc/sysctl.conf /etc/inputrc 输入设备配置文件 /etc/default/useradd 添加用户的默认信息的文件 /etc/login.defs 是用户密码信息的默认属性 /etc/skel 用户信息的骨架 /sbin/nologin 不能登陆的用户 /var/log/message 系统的日志文件 /etc/httpd/conf/httpd.conf 配置http服务的配置文件 /etc/ld.so.conf /etc/my.cnf /etc/httpd/conf/httpd.conf /root/.bash_history /root/.mysql_history /proc/mounts /porc/config.gz /var/lib/mlocate/mlocate.db /porc/self/cmdline
WINDOWS:
C:\windows\system32\drivers\etc\hosts host文件 C:*\apache-tomcat-7.0.1/conf/context.xml、web.xml、server.xml、tomcat-users.xml C:\boot.ini //查看系统版本 C:\Windows\System32\inetsrv\MetaBase.xml //IIS配置文件 C:\Windows\repair\sam //系统初次安装的密码 C:\Program Files\mysql\my.ini //Mysql配置 C:\Program Files\mysql\data\mysql\user.MYD //Mysqlroot C:\Windows\php.ini //php配置信息 C:\Windows\my.ini //Mysql配置信息 C:\Windows\win.ini //Windows系统的一个基本系统配置文件
如果您有任何问题,请跟我们联系!
联系我们
Copyright © 武汉网盾科技有限公司 版权所有 备案号:鄂ICP备2023003462号-5
地址:联系地址:湖北省武汉市东湖新技术开发区武大科技园兴业楼北楼1单元2层
