



服务热线
15527777548/18696195380
发布时间:2022-04-12
简要描述:
上次我们提到网卡层面的丢包过程,这次我们来网上看网络协议栈丢包。背景可能有读者问,我们搞安全的,天天分析丢包干啥?你可能不知道的是对于NIDS,在网络负载流量高的情况下,许多NI...
上次我们提到网卡层面的丢包过程,这次我们来网上看网络协议栈丢包。
可能有读者问,我们搞安全的,天天分析丢包干啥?你可能不知道的是对于NIDS,在网络负载流量高的情况下,许多NIDS会出现丢包现象,所以NIDS仍存在误报、漏报的可能,这时候对于一线和产线的研发来说,排查思路就很关键。
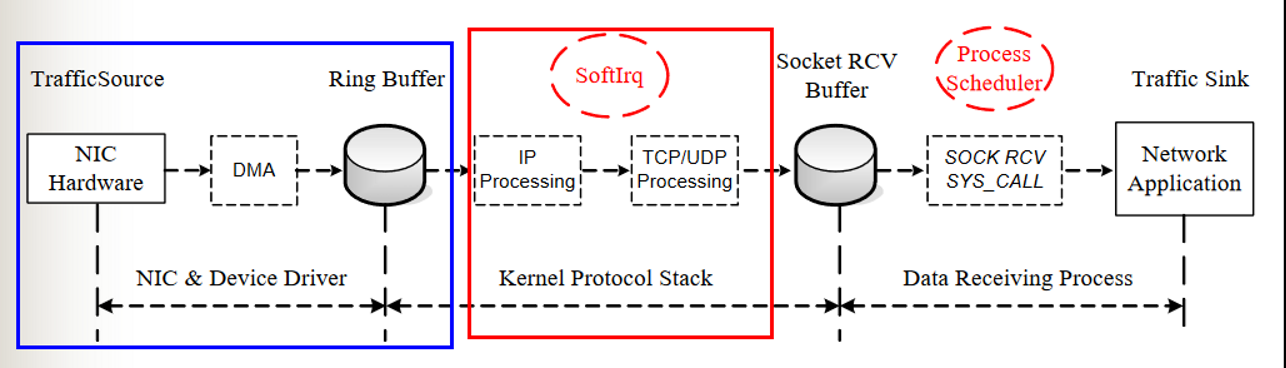
我们先整体看一下数据包传输的整个过程(如图所示):蓝色方框内的是网卡处理数据包,也就是上次分析的内容。红色方框内是网络协议栈处理数据包的过程,这个过程是将Ring buffer的数据包传到socket的接收buffer中。
注:蓝色方框为网卡处理数据的过程,红色方框为网络协议栈处理数据的过程。
那么接下来看看网络协议栈数据的处理过程吧。
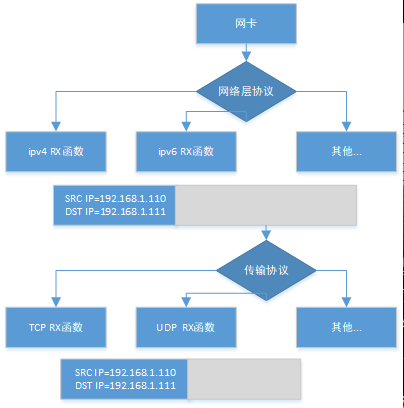
①Ring Buffer的数据首先送到IP层,对IP包进行完整性校验、路由、分片;
②IP层再送到传输层,如果是TCP包,比较复杂,会进行流量控制、拥塞避免、确认机制和重传机制等;UDP包就比较简单了,进行完整性校验,若队列满了,就直接丢弃;
③最后通过SOCKET接口送往应用层。
那网络协议栈这么复杂,我该从哪开始分析呢?
下面介绍一款专用与协议栈丢包分析的工具:dropwatch
dropwatch的定位就是用来分析网络丢包的,它是通过各个协议层释放skb的时候,来收集相关信息判断有没有丢包。
Centos7安装dropwatch
1、官网下载rpm包https://pkgs.org/download/dropwatch
uname -r根据内核版本选择对应的版本:我的是x86_64,所以下载它dropwatch-1.4-9.el7.x86_64.rpm

2、安装dropwatch
rpm -ivh dropwatch-1.4-9.el7.x86_64.rpm
dropwatch的使用
1、dropwatch本身有一个交互命令行,kas指的是加载对应的符号表:dropwatch -l kas,然后start开始跟踪。
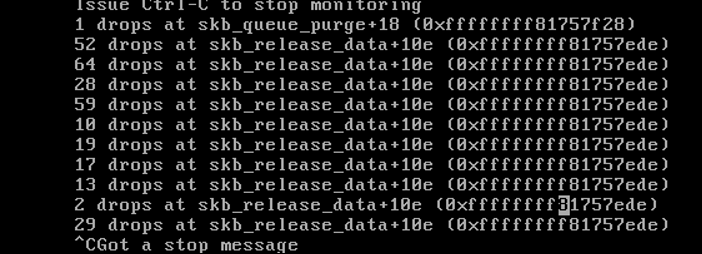
dropwatch 显示在 skb_release_data 附近存在大量丢包现象,并提示丢包信息,信息格式如下所示:
64 drops at skb_release_data + 10e (0xffffffff81757ede)
| 64 | drops at | skb_release_data | + | 10e (0xffffffff81757ede) |
| 丢包数量 | drops at | 函数名 | + | 偏移量 (地址) |
2、进一步确定丢包的位置
grep -w -A 10 tcp_v4_rcv /proc/kallsyms
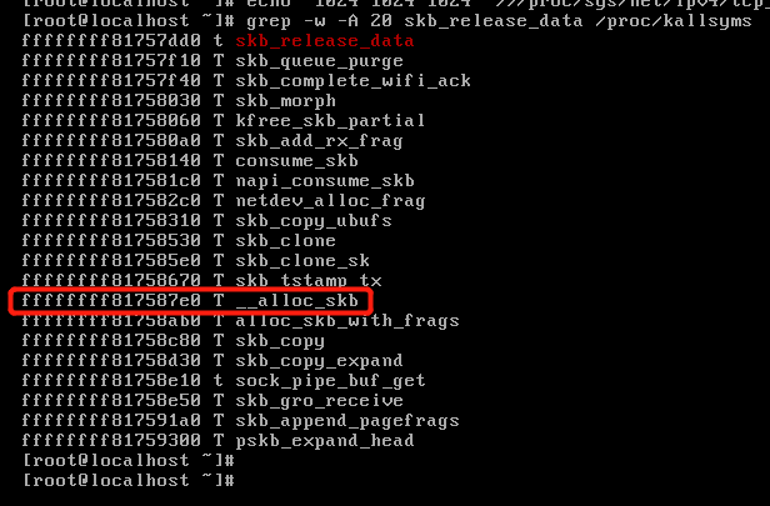
这就定位到了具体的丢包位置是 __alloc_skb。
找到代码中丢包的具体位置后,再来看看代码前后是不是触发了什么限制,如:队列太小了,缓存不够之类的......
以下这段代码来自:linux-5.16.15
__alloc_skb是用于分配缓冲区的函数,由于数据缓冲区和缓冲区的描述结构是两种不同的实体,所以在分配一个缓冲区时,就同时需要分配两块内存。调用kmem_cache_alloc()从缓存中获取一个sk_buff结构,并调用kmalloc_track_caller分配缓冲区。
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
int flags, int node)
{
struct kmem_cache *cache;
struct sk_buff *skb;
unsigned int osize;
bool pfmemalloc;
u8 *data;
/*如果fclone被设置,则从skbuff_fclone_cache中分配,如果没有设置则从skbuff_head_cache中分配 */
cache = (flags
if (sk_memalloc_socks()
/* Get the HEAD */
// 先从内存上分配,cache分配不了就到内存申请
if ((flags
else
skb = kmem_cache_alloc_node(cache, gfp_mask
if (unlikely(!skb))
return NULL;
prefetchw(skb); //写缓存预取址
/* We do our best to align skb_shared_info on a separate cache
* line. It usually works because kmalloc(X > SMP_CACHE_BYTES) gives
* aligned memory blocks, unless SLUB/SLAB debug is enabled.
* Both skb->head and skb_shared_info are cache line aligned.
*/
size = SKB_DATA_ALIGN(size); //边界对齐
size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info)); //边界对齐
data = kmalloc_reserve(size, gfp_mask, node, //分配skb的数据存储区
if (unlikely(!data)) //若是分配失败则清空cache
goto nodata;
/* kmalloc(size) might give us more room than requested.
* Put skb_shared_info exactly at the end of allocated zone,
* to allow max possible filling before reallocation.
*/
osize = ksize(data);
size = SKB_WITH_OVERHEAD(osize);
prefetchw(data + size);
/*
* Only clear those fields we need to clear, not those that we will
* actually initialise below. Hence, don't put any more fields after
* the tail pointer in struct sk_buff!
*/
memset(skb, 0, offsetof(struct sk_buff, tail));
__build_skb_around(skb, data, osize);
skb->pfmemalloc = pfmemalloc;
//子skb初始化
if (flags
//父子skb的总计数在两个skb结构的末尾
fclones = container_of(skb, struct sk_buff_fclones, skb1);
skb->fclone = SKB_FCLONE_ORIG;
refcount_set(
fclones->skb2.fclone = SKB_FCLONE_CLONE;
}
return skb;
nodata:
kmem_cache_free(cache, skb);return NULL;
}我们看到加粗的代码,发现skb数据存储区分配失败之后数据包就被free了,所以很有可能是进行中断拷贝数据包到协议栈的这个过程被丢了。
网络协议栈会丢包的地方很多,这里知识抛砖引玉举一个例子。具体场景还需要具体分析,一般排查时不会先使用这种方法,因为这个会涉及到复杂的内核代码,能否快速定位出问题取决于对内核的熟悉程度。建议先从业务切入,先排除掉应用层可能的问题;若是最后没法从应用层或其他的途径定位问题,再考虑使用dropwatch来排查丢包问题。
2、《深入理解Linux网络技术内幕》
如果您有任何问题,请跟我们联系!
联系我们
Copyright © 武汉网盾科技有限公司 版权所有 备案号:鄂ICP备2023003462号-5
地址:联系地址:湖北省武汉市东湖新技术开发区武大科技园兴业楼北楼1单元2层
