



服务热线
15527777548/18696195380

发布时间:2022-03-10
简要描述:
样本应用宝随手下载一个安装包,本文分析的是作业帮v13.28.0。工具jadx、idapro、unicorn。分析直接将apk拖入jadx,找到入口MyWrapperProxyApplication。继承了WrapperProxyApp...
应用宝随手下载一个安装包,本文分析的是作业帮v13.28.0。
jadx、idapro、unicorn。
直接将apk拖入jadx,找到入口MyWrapperProxyApplication。
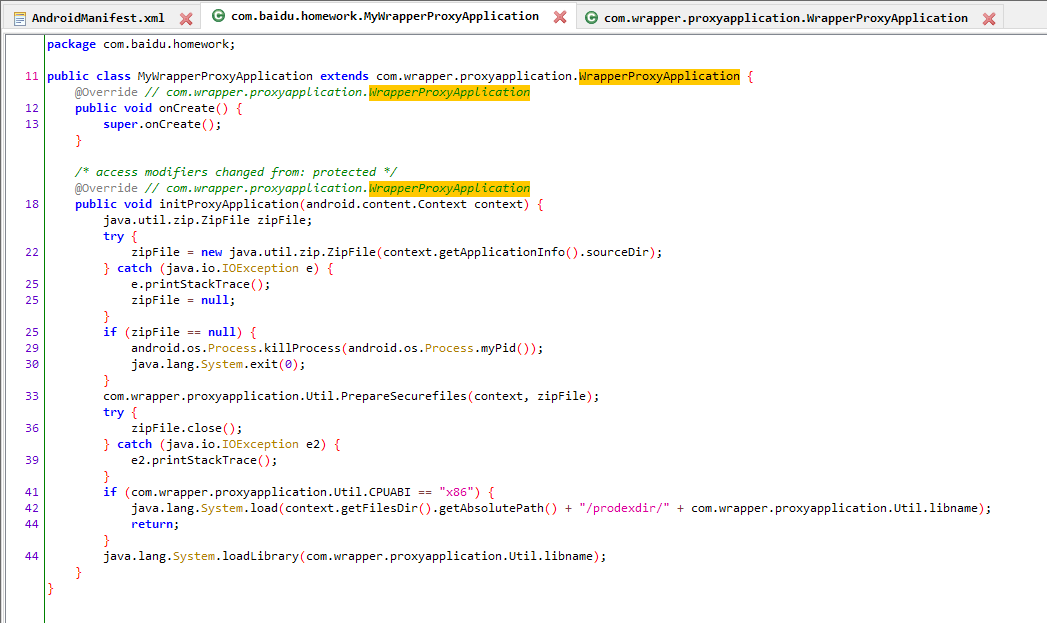
继承了WrapperProxyApplication,在attachBaseContext中调用了initProxyApplication,而initProxyApplication中调用com.wrapper.proxyapplication.Util.PrepareSecurefiles,然后加载libshell-super.2019.so。
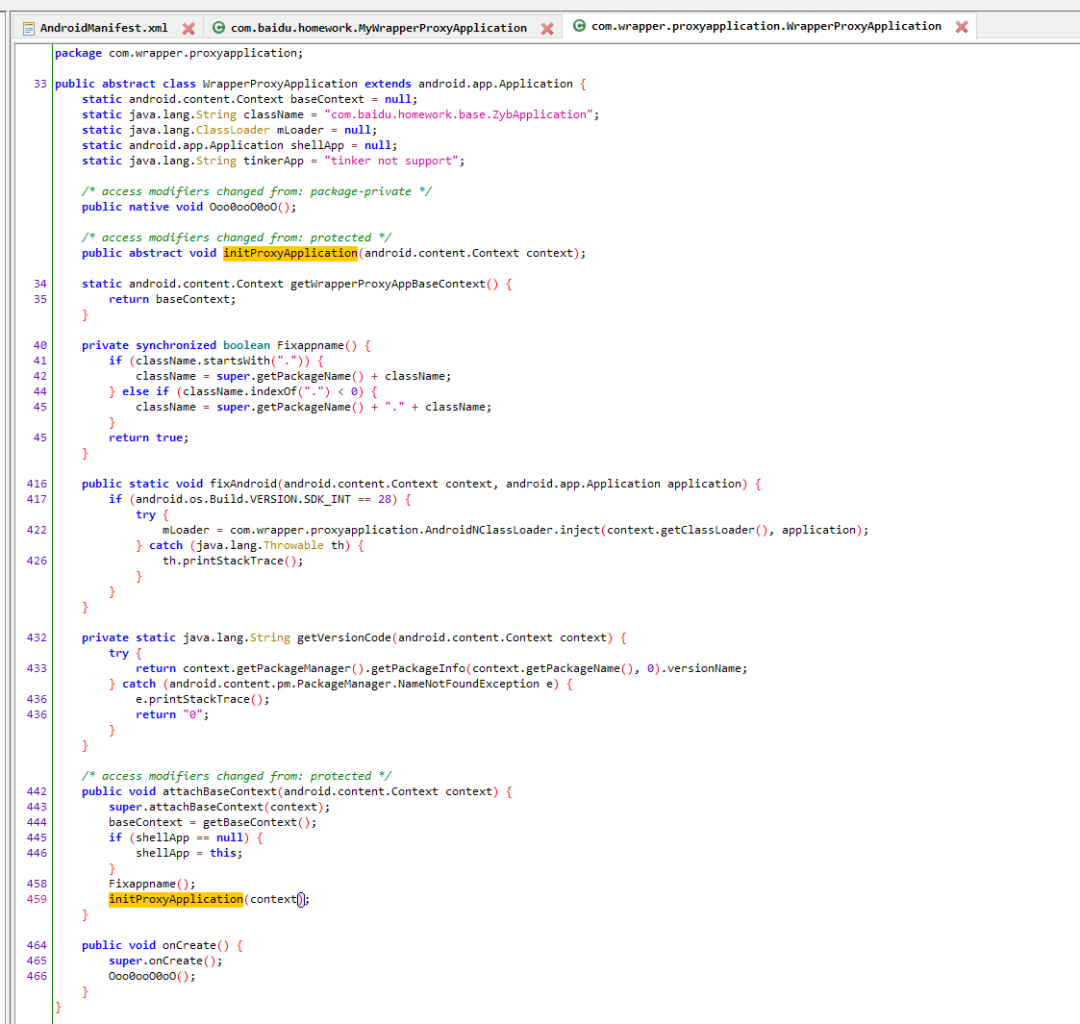
PrepareSecurefiles这个方法反编译出来又长又臭,主要就是检查下/data/data/com.baidu.homework/files/prodexdir目录下的一些文件是否完整。
这些文件都是从assets释放的,主要有两个文件tosversion和0OO00l111l1l。
通过后续分析可知tosversion适用于判断应用升级的,0OO00l111l1l是保存原始dex的加密文件。

然后把libshell-super.2019.so拖入ida进行分析,首先看看.init_array,有一堆函数。
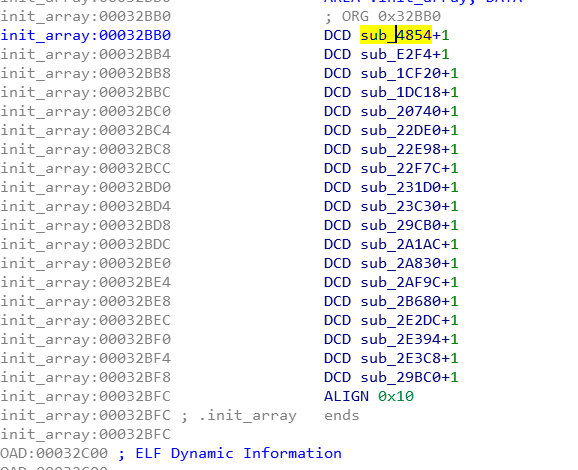
把这些函数挨个大概看下,除了最后一个sub_29BC0都是在做字符串解密,这些字符加密的方式为每个字符串和一个固定的字符进行异或。
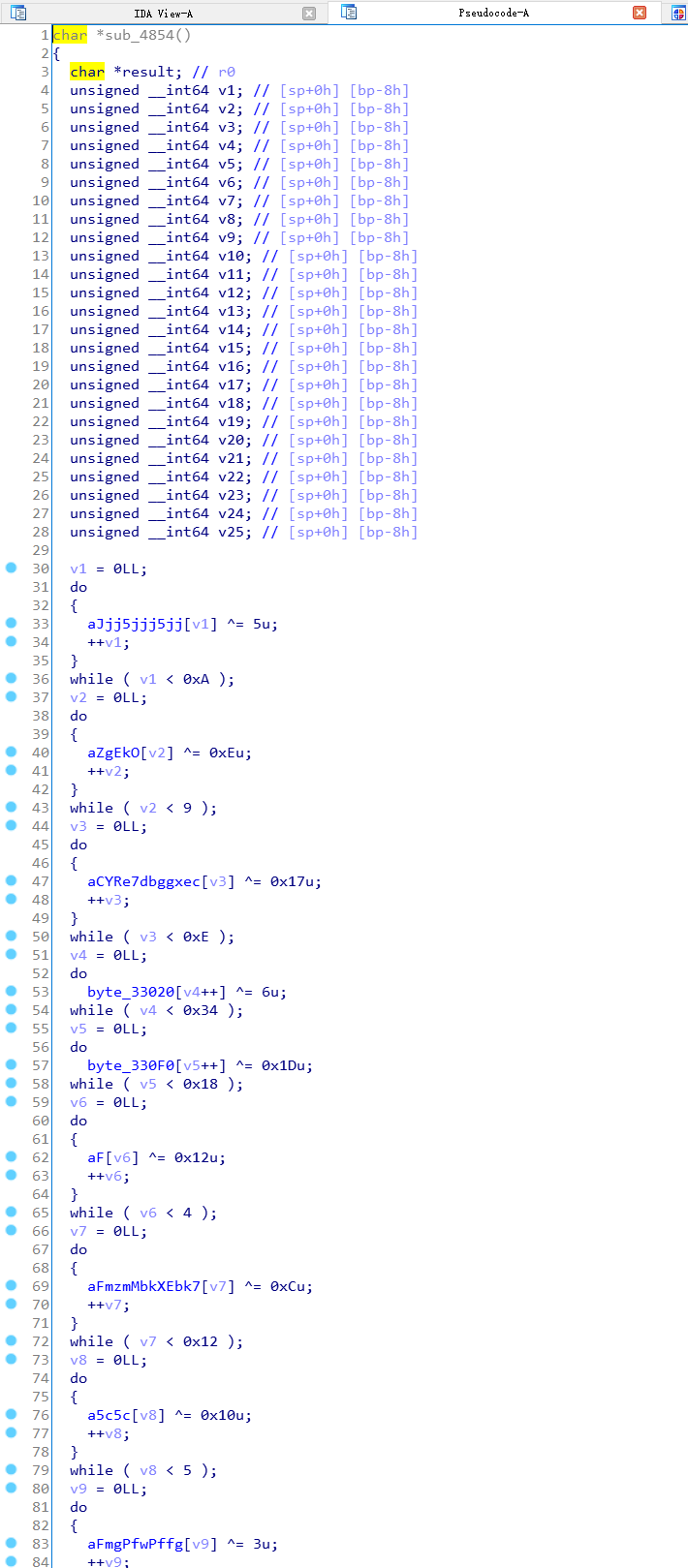
虽然解密的方式十分简单,但是需要处理的字符串数量太多了,手动一个一个处理肯定是不行的,这就需要脚本了。
脚本处理有两种方式:
一种是分析汇编代码,找出需要解密的字符串起始地址、字符串长度、解密key;
另一种是unicorn直接运行.init_array中的函数,然后把运行后的内容直接加载到ida中。
首先来看第一种方法,通过分析可知,每次解密的指令格式都是固定的。
通过第三条指令LDR可以获取到字符串起始地址,第四条有可能是跳转指令B,也可能没有。
通过倒数第四条指令SUBS可以获取到字符串长度,通过EOR.W指令可以获取到用于解密的字符。


根据以上分析结果,写出idc脚本,执行一遍发现,存在解密失败的。
找到失败的地址,发现当字符串长度为1的时候,指令格式不一致。


把这个情况兼容一下,脚本内容如下:
import idc def find_next_chunk(addr): if not idc.is_code(idc.get_full_flags(addr)): return False, None, None, None, None op = idc.print_insn_mnem(addr) if op != 'MOVS' and op != 'MOV.W': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'STRD.W': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'LDR': return False, None, None, None, None arr_start = idc.get_wide_dword(idc.get_operand_value(addr, 1)) + addr + 2 * 3 addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'ADD': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op == 'B': addr = idc.get_operand_value(addr, 0) op = idc.print_insn_mnem(addr) if op != 'LDRD.W': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'LDRB': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'EOR.W': return False, None, None, None, None xor_ch = idc.get_operand_value(addr, 2) addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'STRB': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'ADDS': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op == 'ADC.W': addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'STR': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'SUBS': return False, None, None, None, None arr_len = idc.get_operand_value(addr, 1) addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'STR': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'SBCS.W': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'BCC': return False, None, None, None, None next_addr = idc.next_head(addr) return True, next_addr, xor_ch, arr_start, arr_len elif op == 'STR': addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'ADCS.W': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'STR': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'ADCS.W': return False, None, None, None, None addr = idc.next_head(addr) op = idc.print_insn_mnem(addr) if op != 'BNE': return False, None, None, None, None next_addr = idc.next_head(addr) return True, next_addr, xor_ch, arr_start, 1 else: return False, None, None, None, None def decode_arr(arr_start, arr_len, xor_ch): for addr in range(arr_start, arr_start + arr_len): ch = idc.get_wide_byte(addr) # print hex(ch) idc.patch_byte(addr, ch ^ xor_ch) idc.create_strlit(arr_start, arr_start + arr_len + 1) def proc_func(func_addr): if not func_addr: return # Thumb, func_start_addr+1==func_addr func_start_addr = idc.get_func_attr(func_addr, idc.FUNCATTR_START) func_end_addr = idc.get_func_attr(func_addr, idc.FUNCATTR_END) print hex(func_start_addr), '----->', hex(func_end_addr) addr = func_start_addr while addr < func_end_addr: succ, next_addr, xor_ch, arr_start, arr_len = find_next_chunk(addr) if succ: print hex(addr).ljust(10), hex(xor_ch).ljust(10), hex(arr_start).ljust(10), arr_len decode_arr(arr_start, arr_len, xor_ch) addr = next_addr else: print '*' * 10, hex(addr) addr = idc.next_head(addr) print '' * 3 def decode_str(): idc.auto_wait() start_addr = idc.get_segm_by_sel(idc.selector_by_name('.init_array')) end_addr = idc.get_segm_end(start_addr) addr = start_addr while addr + 4 <= end_addr: func_addr = idc.get_wide_dword(addr) proc_func(func_addr) addr += 4 decode_str()
ida加载运行该脚本,得到解密后的内容。


然后是第二种方法,通过unicorn直接运行.init_array中的解密函数,然后把解密后的内容直接加载到ida中。
import unicorn import idc def func_block_handle(uc, address, size, user_data): if address in (0, 0x29BC0): uc.emu_stop() def decode_str(): idc.auto_wait() dir_path = r'/Users/lll19/Downloads/legu/' bin_len = idc.prev_addr(idc.BADADDR) bin_len = (bin_len / 0x1000 + (1 if bin_len % 0x1000 else 0)) * 0x1000 bin_path = dir_path + 'elf_bin' idc.savefile(bin_path, 0, 0, bin_len) f_bin = open(bin_path, 'rb') bin_bytes = bytes(f_bin.read()) f_bin.close() stack_size = 0x100000 stack_top = bin_len stack_bottom = stack_top + stack_size uc = unicorn.Uc(unicorn.UC_ARCH_ARM, unicorn.UC_MODE_THUMB) uc.hook_add(unicorn.UC_HOOK_BLOCK, func_block_handle) uc.mem_map(0, bin_len) uc.mem_write(0, bin_bytes) uc.mem_map(stack_top, stack_size) start_addr = idc.get_segm_by_sel(idc.selector_by_name('.init_array')) end_addr = idc.get_segm_end(start_addr) addr = start_addr while addr + 4 <= end_addr: func_addr = idc.get_wide_dword(addr) addr += 4 if not func_addr: continue print hex(func_addr) func_end_addr = idc.find_func_end(func_addr) uc.reg_write(unicorn.arm_const.UC_ARM_REG_SP, stack_bottom) uc.reg_write(unicorn.arm_const.UC_ARM_REG_LR, 0) uc.emu_start(func_addr, func_end_addr) f_save = open(bin_path, 'wb') f_save.write(str(uc.mem_read(0, bin_len))) f_save.close() idc.loadfile(bin_path, 0, 0, bin_len) decode_str()
然后开始分析JNI_OnLoad,这个函数被混淆了,于是继续unicorn走起。
根据输出可知,该函数主要执行了以下几个操作:
通过RegisterNatives注册WrapperProxyApplication.Ooo0ooO0oO(),
调用0x1f668处的函数进行上下文初始化,调用0x2B604处的函数生成解密key,调用0xcea8处的函数加载dex。
先分析下sub_1f668处的初始化过程,东西比较多就不贴图了
首先是一些常规操作,获取vm类型、PackageInfo、ActivityThread、ClassLoader等。
然后是通过GetMethodID获取之前注册的WrapperProxyApplication.Ooo0ooO0oO()的MethodID,然后在MethodID指向的内存(通过Android源码可知,MethodID实际是ArtMethod对象的指针)查找之前注册的函数地址,找到后保存该偏移值,后面会通过这个偏移值对系统native方法进行hook。
再然后就是加载0OO00l111l1l,解析该文件,把该文件的各种数据指针缓存起来,用于后面数据解密。
再然后判断系统是否升级,读取prodexdir/.updateIV.dat中缓存的数据与libart.so和dex2oat的大小进行比较,如果不相等则将.odex和.vdex文件删除并更新.updateIV.dat。
0OO00l111l1l数据结构如下,前4字节为dex的数量,后面分别为三种数据,通过后面分析可知:
第一部分数据为压缩的dex,其中的指令被抽取了;第二部分为压缩且加密的索引数据;第三部分为压缩且加密的指令数据。

看下sub_2B604的代码,比较简单,读取文件内容与byte_31391处的字符处理后存放在byte_36A8C。

大概分析下sub_cea8过程,调用sub_1CD90,对DexFile.defineClassNative()进行hook,原理是先获取defineClassNative的MethodID,然后通过先前获取到的偏移值,将该函数的本地函数指针保存起来,再通过RegisterNatives重新为该函数注册一个本地函数。
调用java方法com.wrapper.proxyapplication.MultiDex.preparetoinstallDexes(),获取dexElements,hook几个系统函数mmap、execve、execv,hook的方式是通过遍历重定位项实现的。这个几个hook在我分析的过程中没用上。
多线程调用函数sub_CE14解密加载dex并opt,等待所有线程结束后,获取mCookie缓存起来,取消之前hook的几个系统函数,并设置几个环境变量,
构造当前应用的原始application,并调用其attach()方法。
剩下的流程都不重要了,现在只关心解密函数sub_CE14,
首先调用sub_CC2C进行dex解压缩并写入/data/data/com.baidu.homework/files/prodexdir下的dex文件,再调用java方法com.wrapper.proxyapplication.MultiDex.installDexes()进行dex替换。
解压缩函数为sub_2B2AC,看看反编译代码,全是各种字符操作,具体算法就不看了,待会儿直接上unicorn。
dex加载成功后调用sub_10EB4进行指令解密。
首先对第二部分数据进行解密,解密函数为sub_2315C,解密完成后调用sub_2B2AC解压缩,再调用sub_115F4生成每个类结构的索引。
然后对第三部分数据进行解密,解密函数为sub_2315C,解密完成后调用sub_2B2AC解压缩,得到所有抽取的指令。
现在只剩最后一步了,那就是在class加载的时候,对抽取的指令进行填充,这里需要分析的是前面hook的DexFile.defineClassNative(),对应的函数为sub_1C900,其主要内容如下。
首先查找class所在的dex和对应的索引(sub_22B90),然后进行指令填充(sub_101B8),最后调用原来的函数地址。

sub_22B90的代码和对应的数据如下,通过分析可知,从偏移8开始是一个hash表,每个表项3个字段,分别为hash值、类名偏移、类结构索引偏移。
偏移为4的字段为hash表的大小。
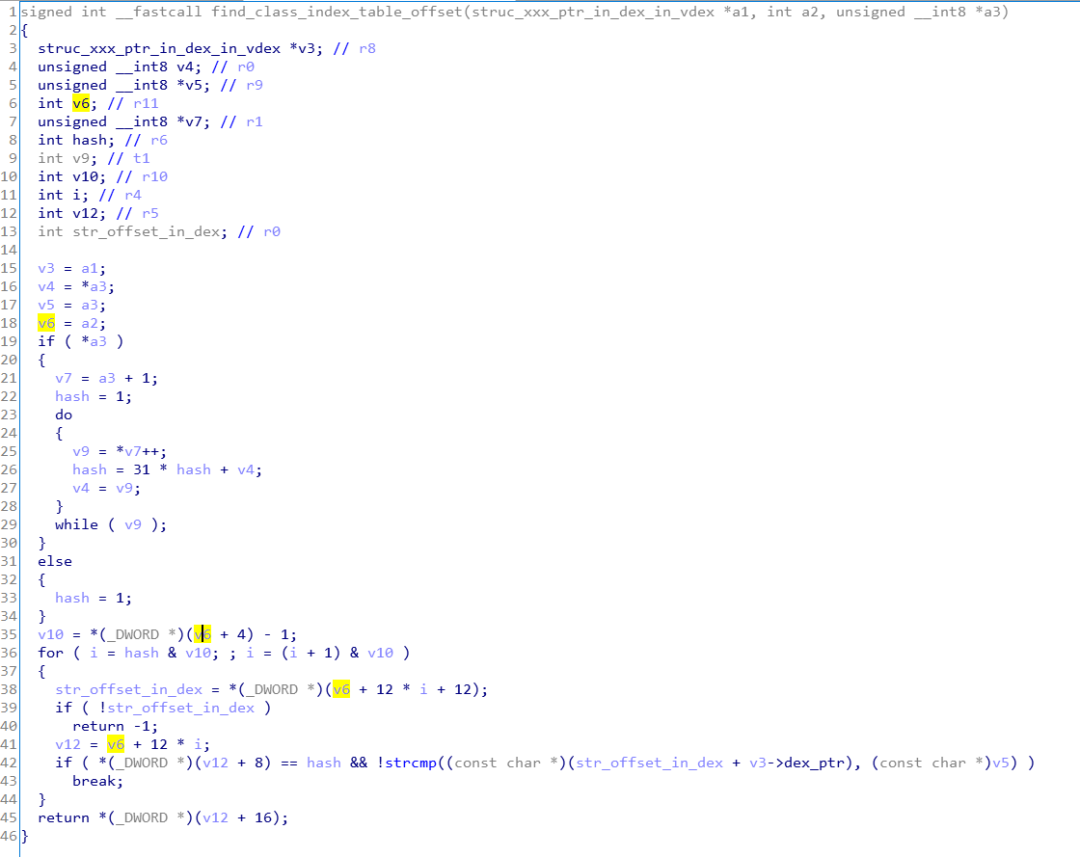

函数sub_101B8对class指令进行填充,函数被混淆了,既然这样,也就不看了,直接unicorn。

到此为止,所有的流程都分析完了。
开始准备脱壳脚本,需要模拟执行的函数流程分为以下几部分:
1、执行0x2B604处的代码。读取tosversion文件的内容,处理后作为解密的key(该处只读取了16个字节,但是解密的时候,复制了32字节的key,但是不影响,实际执行解密的时候只用了前16字节)。
2、循环执行0x2B2AC处的代码。解压出所有被抽取指令的dex。
3、循环执行0x2315C、0x2B2AC、0x115F4这三处代码,分别对应class信息的解密、解压、建索引。
4、循环执行0x2315C、0x2B2AC这两处代码,分别对应指令的解密、解压。
5、遍历所有dex的hash表,循环执行0x101b8处的代码进行指令修复。
完整的脱壳脚本就不贴了,提示超出字数限制了,我把它放在附件里面了。
样本打包后附件大小也超限制了。
样本我放网盘了,附件只保留了脚本文件。
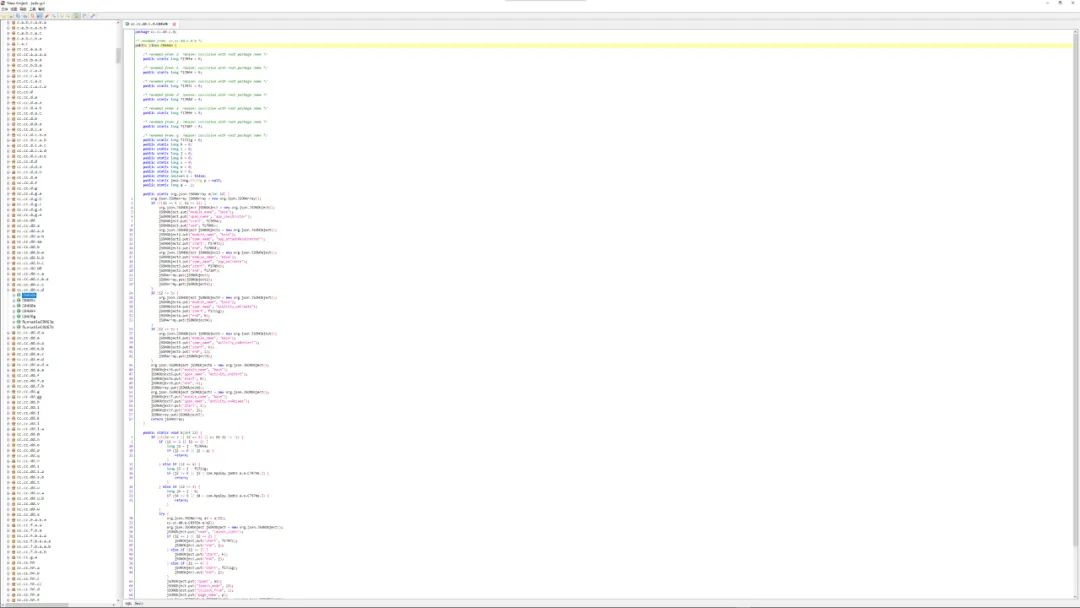
贴个脱壳修复后的图:
如果您有任何问题,请跟我们联系!
联系我们
Copyright © 武汉网盾科技有限公司 版权所有 备案号:鄂ICP备2023003462号-5
地址:联系地址:湖北省武汉市东湖新技术开发区武大科技园兴业楼北楼1单元2层
